在当今的互联网世界中,PHP 蜘蛛池是一种被广泛应用的技术手段。它通过模拟蜘蛛的行为,快速抓取大量的网页内容,为搜索引擎优化(SEO)等领域提供了有力的支持。本文将详细介绍 PHP 蜘蛛池的原理、实现方法以及实际应用案例,帮助读者更好地理解和使用这一技术。
PHP 蜘蛛池的原理基于模拟蜘蛛的抓取行为。蜘蛛是搜索引擎用来收集网页信息的程序,它们按照一定的规则和策略在互联网上爬行,抓取网页并提取其中的内容。PHP 蜘蛛池通过编写 PHP 脚本,模拟蜘蛛的行为,向目标网站发送请求,获取网页内容,并将其存储在本地或数据库中。
在实现 PHP 蜘蛛池时,需要考虑多个方面的问题。首先是请求的模拟,要模拟蜘蛛的请求头、请求参数等,以避免被目标网站识别为非法请求或被屏蔽。其次是抓取策略的制定,需要根据需求确定抓取的范围、深度和频率等,以提高抓取效率和质量。还需要考虑数据的存储和管理,如何将抓取到的网页内容存储在本地或数据库中,以便后续的分析和使用。
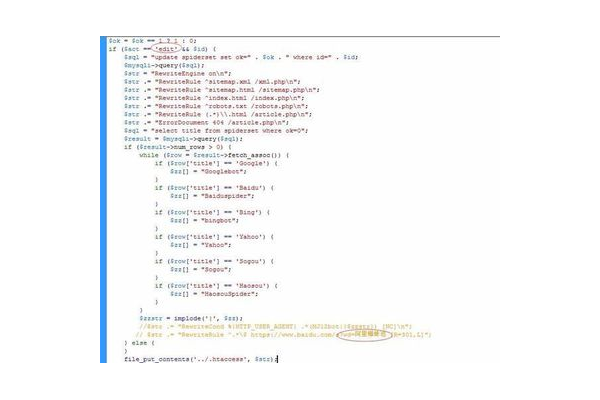
以下是一个简单的 PHP 蜘蛛池实现示例:
```php
// 设置请求头
$headers = array(
'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Referer: http://example.com'
);
// 目标网站列表
$targetSites = array(
'http://www.example1.com',
'http://www.example2.com',
'http://www.example3.com'
);
// 抓取函数
function crawlSite($site) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $site);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_USERAGENT, $headers['User-Agent']);
curl_setopt($ch, CURLOPT_REFERER, $headers['Referer']);
$response = curl_exec($ch);
curl_close($ch);
return $response;
}
// 抓取目标网站
foreach ($targetSites as $site) {
$content = crawlSite($site);
// 处理抓取到的内容
//...
}
?>
```
在上述示例中,通过设置请求头模拟了蜘蛛的行为,然后遍历目标网站列表,调用`crawlSite`函数抓取每个网站的内容。在实际应用中,可以根据需求对抓取函数进行扩展和优化,例如添加错误处理、多线程抓取等功能。
PHP 蜘蛛池在实际应用中有广泛的用途。它可以用于搜索引擎优化(SEO),通过抓取大量的网页内容,为网站提供更多的关键词和内容,提高网站在搜索引擎中的排名。它可以用于数据采集,获取互联网上的各种信息,例如新闻、产品信息、用户评论等,为数据分析和挖掘提供数据支持。PHP 蜘蛛池还可以用于网站监测,及时发现网站的变化和异常情况,保障网站的正常运行。
需要注意的是,使用 PHP 蜘蛛池也存在一些风险和法律问题。如果未经授权抓取他人网站的内容,可能会侵犯他人的知识产权或违反法律法规。因此,在使用 PHP 蜘蛛池时,必须遵守相关的法律法规,尊重他人的知识产权,不得进行非法的抓取行为。
PHP 蜘蛛池是一种强大的技术手段,可以为 SEO、数据采集和网站监测等领域提供有力的支持。通过合理的设计和使用,可以发挥其优势,提高工作效率和质量。但同时也需要注意风险和法律问题,确保合法合规地使用这一技术。
评论列表